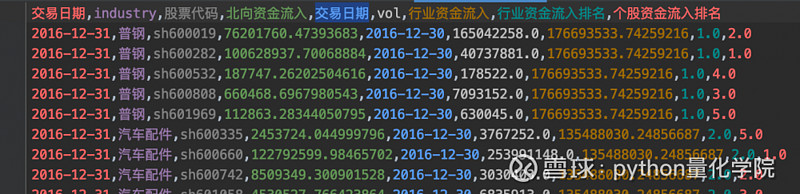
数据整理完毕选股针对新的北向资金持股明细数据。直接选股、行业配合选股各自含茅台、剔除茅台版行业配合选股策略包含茅台资金流入前2行业前5只股票剔除茅台资金流入前2行业前5只股票北向资金流入选股策略包含茅台。选10只资金流入前十结论更正了回测结论1。数据中的上证指数数据主要就是用于补齐交易日期#===计算北向资金每股资金流入、流出#读入上证指数。top_flow就是上面算好的资金链排名数据选股.py选股代码主要更改是在rank那一步。
依旧是《北向资金交易能力一定强吗》这篇研报,尝试用代码实现一下当中的一个选股策略,看看真实效果如何。
更正了回测,核心代码已显示
选股策略概述
筛选月频流入前2行业各选行业内流入前 5 股票,等权买入。
注:本文用的是净流入
数据准备
在最开始先说一下需要用到的数据有:
北向资金持股明细(tushare提供): sgt_hold_detail,包含个股持有量、持有比例、所属行业、地区等字段
A股所有股票日K线数据: df_daily
上证指数: index_data
数据整理
在数据整理的过程中,主要分成2步:
缺失值处理
在北向资金持股明细中,其个股持有量表示的是当日的存量,而当其将个股全部抛出时,则持股量为0,但并不会出现在持股明细中。
即,预期持股明细表现为:
对这部分数据df_ts进行缺失值处理。大致分为两步:补齐交易日期;缺失值处理。
数据中的上证指数数据主要就是用于补齐交易日期

# ===计算北向资金每股资金流入、流出# 读入上证指数,用于补齐交易日期trade_date = pd.read_csv('./data/index_data/sh000001.csv',
parse_dates=['trade_date'], usecols=['trade_date'])
df_flow = sgt_hold_detail.groupby('ts_code').apply(calc_northdata_inflow, trade_date=trade_date['trade_date'])
数据整理后,我们更新了个股日线的字段,也获取了新的北向资金持股明细数据。
这一步比较耗时,个人觉得如果改成数据库会快点,也期待其他大佬的优化建议。
数据整理完毕
选股
针对新的北向资金持股明细数据,我们可以直接进行股票选取。
分为两步:
找出每月资金流入前2的行业
找出前2行业中,每月资金流入前5的股票
这部分代码逻辑比较简单,此处就不细说了,直接上代码。
最后选出的股票数据我直接上传文件了。
内容大致是这样:
策略回测选股数据整理.py
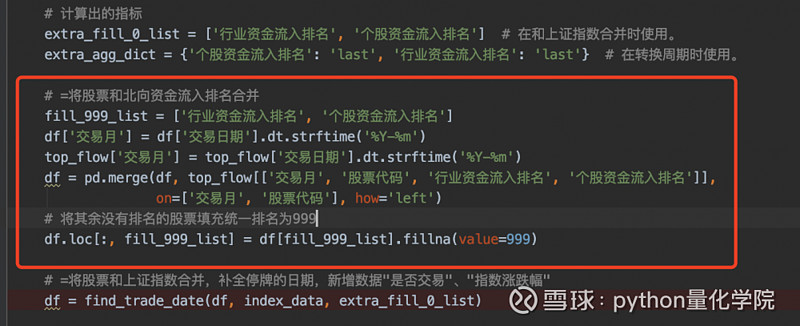
选股数据整理的代码基本没怎么变,就是加了一条合并,需要把之前整好的资金流排名的数据合并到个股数据里面去,方便后面选股
具体代码和加入的位置看截图:
calculate_by_stock函数里,top_flow就是上面算好的资金链排名数据
选股.py
选股代码主要更改是在rank那一步,由于在第一步整理数据的时候已经有了排名,我们不需要进行rank计算了。
但有一个新的问题:由于我们在计算北向资金流入排名的时候,剔除了整月资金流出的情况,而有几个月就是整月资金都是流出的,所以这个月是空的,没有选股的。
那么我们需要对这种情况进行处理,此处的处理思路是:继续按照上月选股进行计算
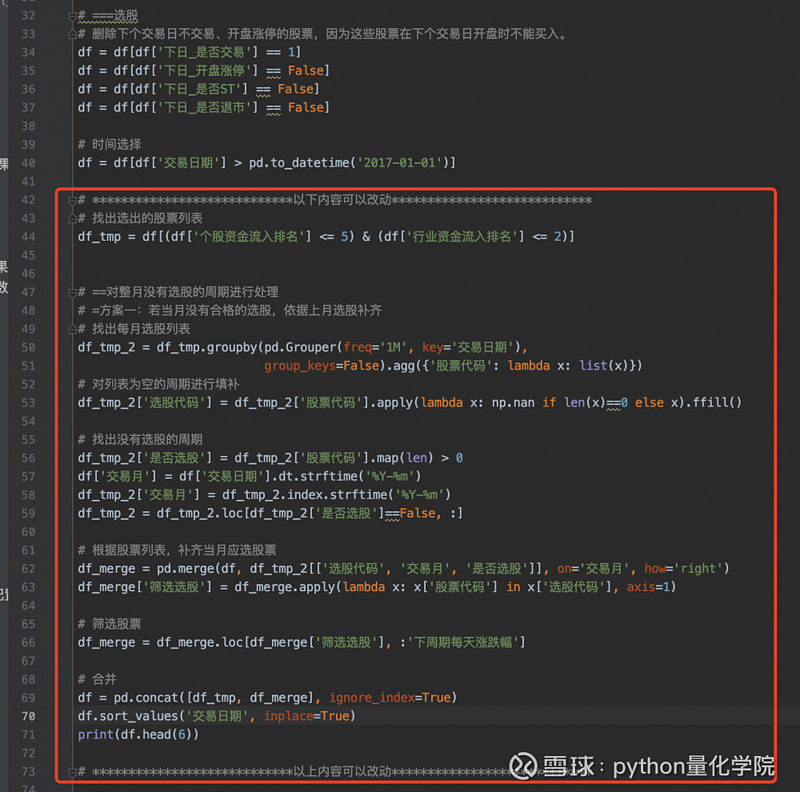
各位也可以考虑这个月就不进行买卖了,随意发挥。
接下来是回测内容
因为考虑到茅台本身的特殊性,这里回测了四个版本:直接选股、行业配合选股各自含茅台、剔除茅台版
行业配合选股策略包含茅台
资金流入前2行业前5只股票
剔除茅台
资金流入前2行业前5只股票
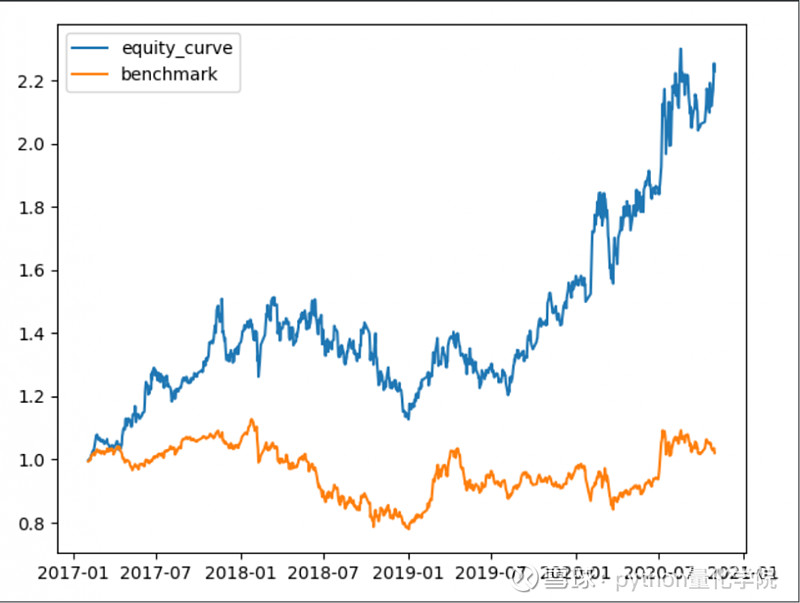
北向资金流入选股策略包含茅台,选10只
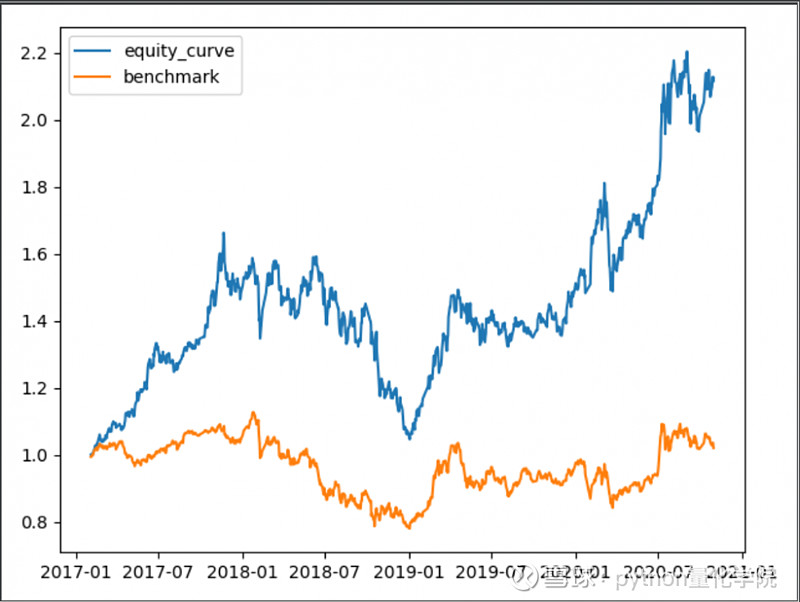
剔除茅台,选10只
资金流入前十
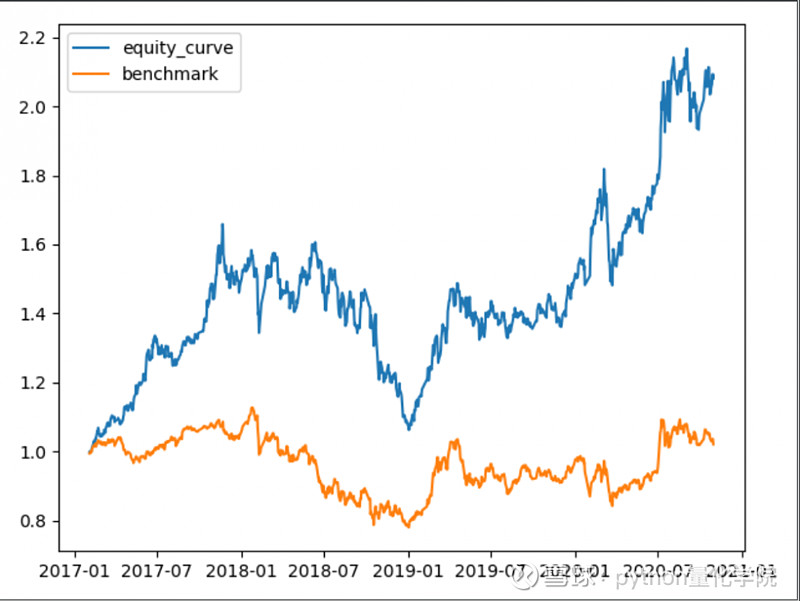
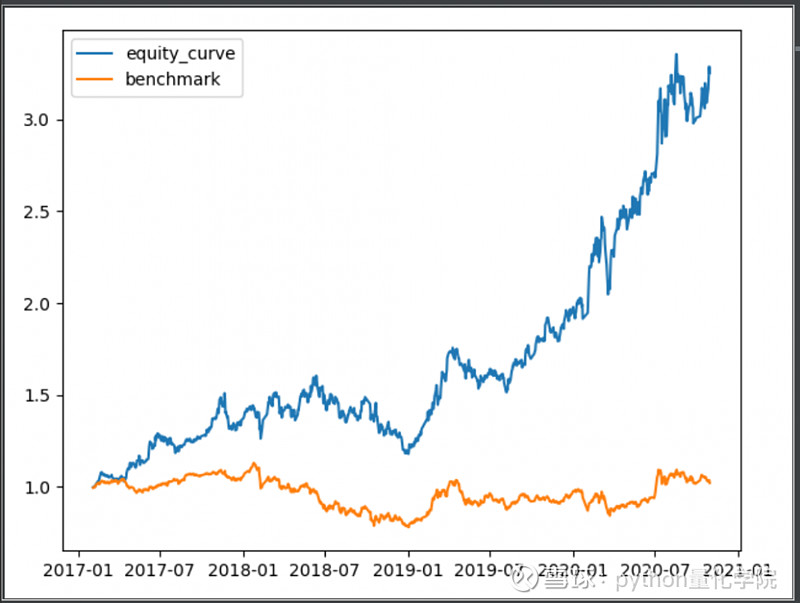
结论
更正了回测
结论1:行业选股的回撤明显小于直接选股
结论2:白酒对行业选股的收益率影响较为明显
结论3:年化收益率37%,收益率很不错。
附件下载:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++
以上非完整内容